2024. 4. 29. 18:32ㆍArchitecture/A.I
2024.04.19 - [Architecture/A.I] - ai? 맨땅에 헤딩 -1(langChain)
2024.04.24 - [Architecture/A.I] - ai? 맨땅에 헤딩 -2(langChain)
2024.04.26 - [Architecture/A.I] - ai? 맨땅에 헤딩 -3(langChain)
오늘은 튜토리얼로 LangChain에서 Vector DB에 저장하고 검색하는 부분이 있었는데
해당 Vector DataBase 관련해서 학습을 해보도록 하겠습니다.
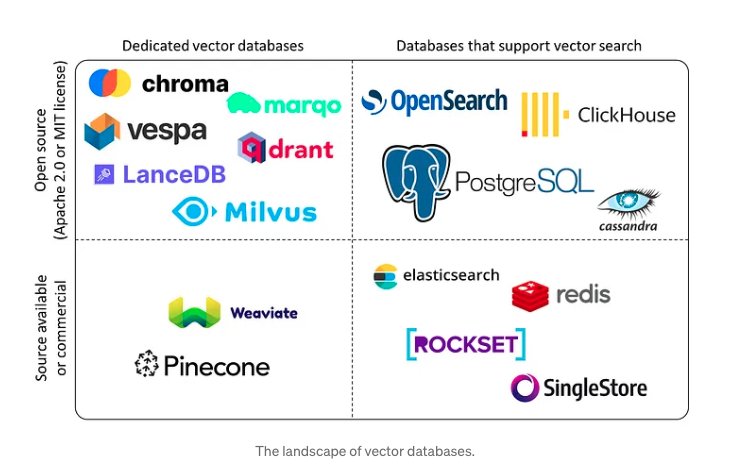
벡터 데이터베이스의 종류로는 아래와 같습니다.
오픈소스는 상단에 있는 친구들 입니다.
오픈소스 중 2가지로 나눠지는데
vector databases 와 supoort vector search를 해주는 databases 입니다.
벡터 데이터베이스의 기초는 데이터 인덱싱에 있습니다.
역인덱싱과 같은 기술을 통해 벡터데이터베이스는 벡터 특징을 그룹화하고
인덱싱하여 유사성 검색을 효율적으로 수행 할 수 있습니다.
관련해서 OLAP(Online Analitycal processing) 데이터베이스는 데이터들을 통합하고 분석하기 위한 영역을 의미 합니다.
말 그대로 분석하기 위한 데이터이기 때문에 갱신을 할 필요성이 적고 압축률이 좋습니다.
그중 크로마는 실시간 OLAP데이터베이스 위에 구축된 벡터 데이터베이스 입니다.
Chroma의 창시자인 Jeff Huber는 Twitter에서 Chroma가 곧 ClickHouse의 의존성을 제거하고
완전한 클라우드 기반 데이터베이스가 될꺼라 답했습니다.

위와 같은 내용과 더불어 회사 크루중에 한분이 LangChain+Croma 벡터DB를 사용하는 사례를 발표한적이 있어서
더욱 관심이 가게 되었습니다.
Chroma의 사이트는 아래와 같습니다.
https://docs.trychroma.com/
Chroma는 오픈소스 임베딩 데이터베이스라고 합니다.
Chroma는 LLM apps를 빌딩하는데 쉽게 만들어준다고 합니다.
- 지식, 사실, 기술을 LLM에 쉽게 플러그인 할 수 있습니다.
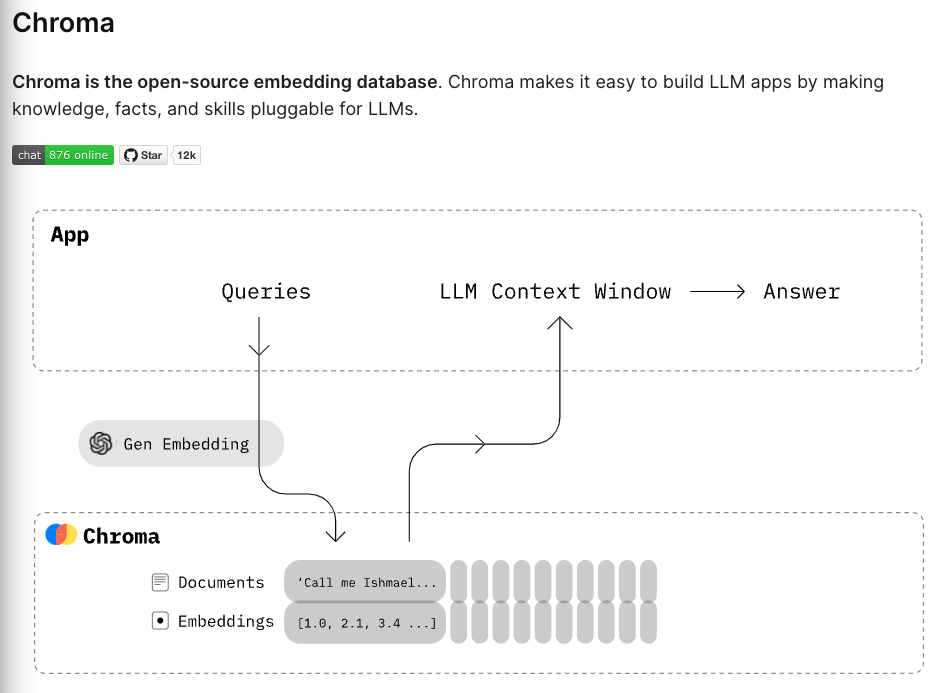
위의 그림은 벡터 DB의 역할을 보여주는 그림입니다.
저번 시간에는 FAISS( Facebook AI Similarity Search) vector store에 저장을 하였는데
이번 시간에는 Chroma에 저장을 해보겠습니다.
Chroma 사용해보기
첫번째로 chromadb를 install 합니다.
pip3 install chromadb
많은 언어에서 Chroma를 support 해주지만 역시나 python이 in-memory까지 지원을 해줍니다.
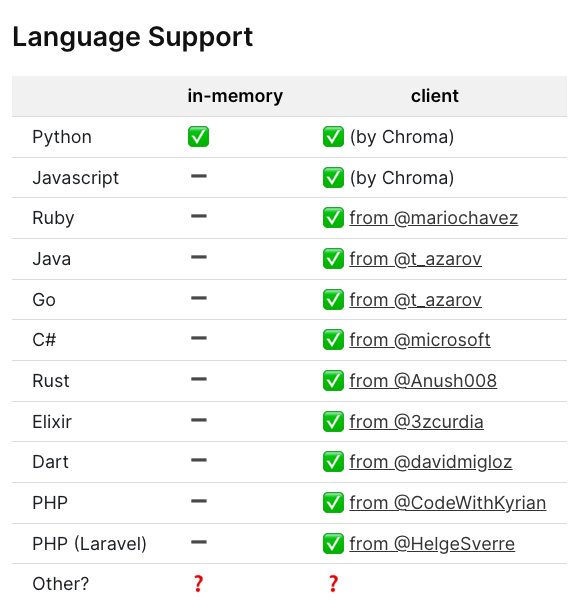
두번째로 Chroma Client를 만들어 봅니다.
import chromadb
chroma_client = chromadb.Client()세번째로 Collection을 만들어 봅니다.
Collections은 embeddings, documents 그리고 metadata를 저장하는 곳 입니다.
아래처럼 my_collection이라는 이름으로 생성할 수 있습니다.
collection = chroma_client.create_collection(name="my_collection")네번째로 some text documents를 컬렉션에 저장합니다.
또한 Chroma는 텍스트를 저장하고 토큰화, 임베딩 및 인덱싱을 자동으로 처리 합니다.
collection.add(
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)이미 embedding을 직접 생성하였다면 아래와 같이 load가 가능 합니다.
collection.add(
embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)다섯번째로 Query the Collection
query text 목록으로 컬렉션을 쿼리(질의)할 수 있으며
Chroma는 n개의 가장 유사한 결과를 반환 합니다.
results = collection.query(
query_texts=["This is a query document"],
n_results=2
)Chroma에 저장된 데이터는 일시적이므로 스크립트 프로토타입을 쉽게 만들수 있습니다.
또한 Chroma를 영구적으로 만드는 것은 쉬우므로 생성한 모든 컬렉션을 재사용하고
나중에 더 많은 문서를 추가 할 수 있습니다.
클라이언트를 시작할 때 데이터를 자동으로 로드하고 클라이언트를 닫을 때 자동으로 저장합니다.
위 소스들을 취합하면 아래와 같습니다.
import chromadb
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="my_collection")
collection.add(
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)
results = collection.query(
query_texts=["This is a query document"],
n_results=2
)
results를 print해보면 아래와 같습니다.
print(results)
{
'ids': [
['id1', 'id2']
],
'distances': [
[0.7110877633094788, 1.0109351873397827]
],
'metadatas': [
[{
'source': 'my_source'
}, {
'source': 'my_source'
}]
],
'embeddings': None,
'documents': [
['This is a document', 'This is another document']
],
'uris': None,
'data': None
}다음 시간에 좀 더 알아보겠습니다~~
'Architecture > A.I' 카테고리의 다른 글
| ai? 맨땅에 헤딩 -5(langChain) : langsmith 셋팅 및 tracing해보기!! (0) | 2024.05.13 |
|---|---|
| ai? 맨땅에 헤딩 -3(langChain) : 주요 컴포넌트 체크! (0) | 2024.04.26 |
| ai? 맨땅에 헤딩 -2(langChain) : 튜토리얼 따라해보기! (0) | 2024.04.23 |
| ai? 맨땅에 헤딩 -1(langChain) : ai와 공생하기! (0) | 2024.04.19 |
| 챗GPT (0) | 2023.03.23 |